
Linked data
TLDR:
Organising things is easier in an excel sheet than a word document. The current web is a giant word document. We need platforms to make it more excel like.
Excel Word
You remember the attendance registers in the 'Old School'. Everyday teachers in my school would have to 'mark' attendance of all students in the register.
Let's imagine for a moment that instead of 'marking' they 'logged' the attendance in good-ole sentences.
- Shreyas was present on 17 July 1999 Morning session
- Ashish was present on 17 July 1999 Morning session
- Shashi was present on 17 July 1999 Afternoon session
...
Good luck counting and keeping tabs on the number of holidays taken by each student at the end of the month.
The good part is that no one takes attendance this way. We have specialised books with neatly laid out rows and columns, there were also times when teachers would hand-draw these grids for each date with a long ruler and red ink. Thanks to these organised grids, counting now would be a trivial and short exercise. There could be orders of magnitude of difference in time and effort needed to derive the same insights purely based on how we represent ideas and information.
What got unlocked when people transitioned from representing numbers from characters a.k.a Roman Numerals such as M, X, V, I to symbols such as 1000, 10, 5, 1? We then turned around to represent numbers with alphabet notations leading to the birth of algebra.
Did the representation of numbers on a line lead to the birth of calculus?
One cannot overstate the importance of how we represent our ideas and knowledge.
Don't take my word for it. Here's the overly quote from Einstein
“We owe a lot to the Indians, who taught us how to count, without which no worthwhile scientific discovery could have been made.”
Albert Einstein
How we represent ideas determines what we can do with them and what evolves from it.
WORD Wide Web
One of the reasons why people are spending countless hours doing 'research' online is because we are trying to glean structured data out of soupy text in a giant document consisting of billions of pages.
It's like the teacher from school running a query
"Number of days Akshay was present this October" only to get the search snippet
"Akshay was absent on Wednesday"
Which links to the full log of everyone's attendance.
While full prose style sentences are good for storytelling they aren't the best for capturing attendance and they definitely aren't the best tool for publishing all information on the web.
In an ideal world when I'm looking for a coworking space in Bengaluru, what I want to see is a comprehensive list of coworking spaces with filters for prices, locations, and recommendations from friends. Instead we're drowning in a sea of listicles.
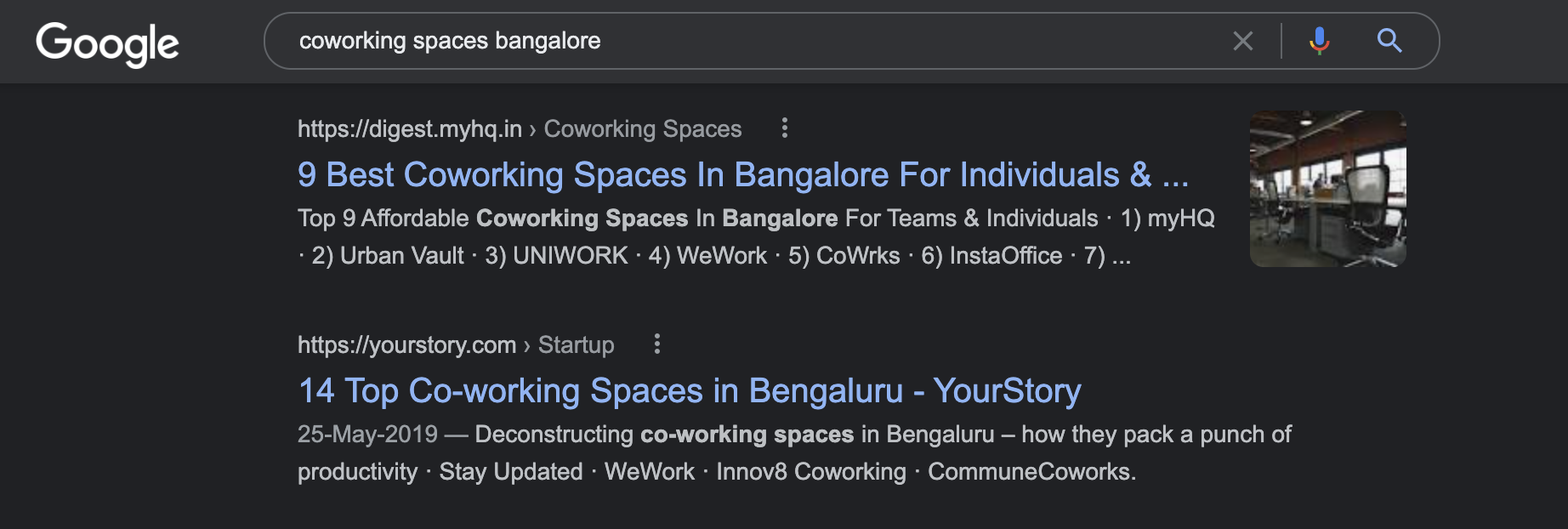
The diligent ones or interns will now create a spreadsheet and come up with this 'research', manually creating a Google Spreadsheet (or a Notion/Airtable if they're cooler) and finally pick the right one.
Here's another story to indicate the current problem of discoverability. In Apr 2021 I built a small tool that allows one to make twitter lists automatically. Apart from Reddit, Hackernews, Product hunt and my social media I didn't really share it anywhere else. I wish there was some sort of a global registry to list my tool as relevant for creating lists on twitter.
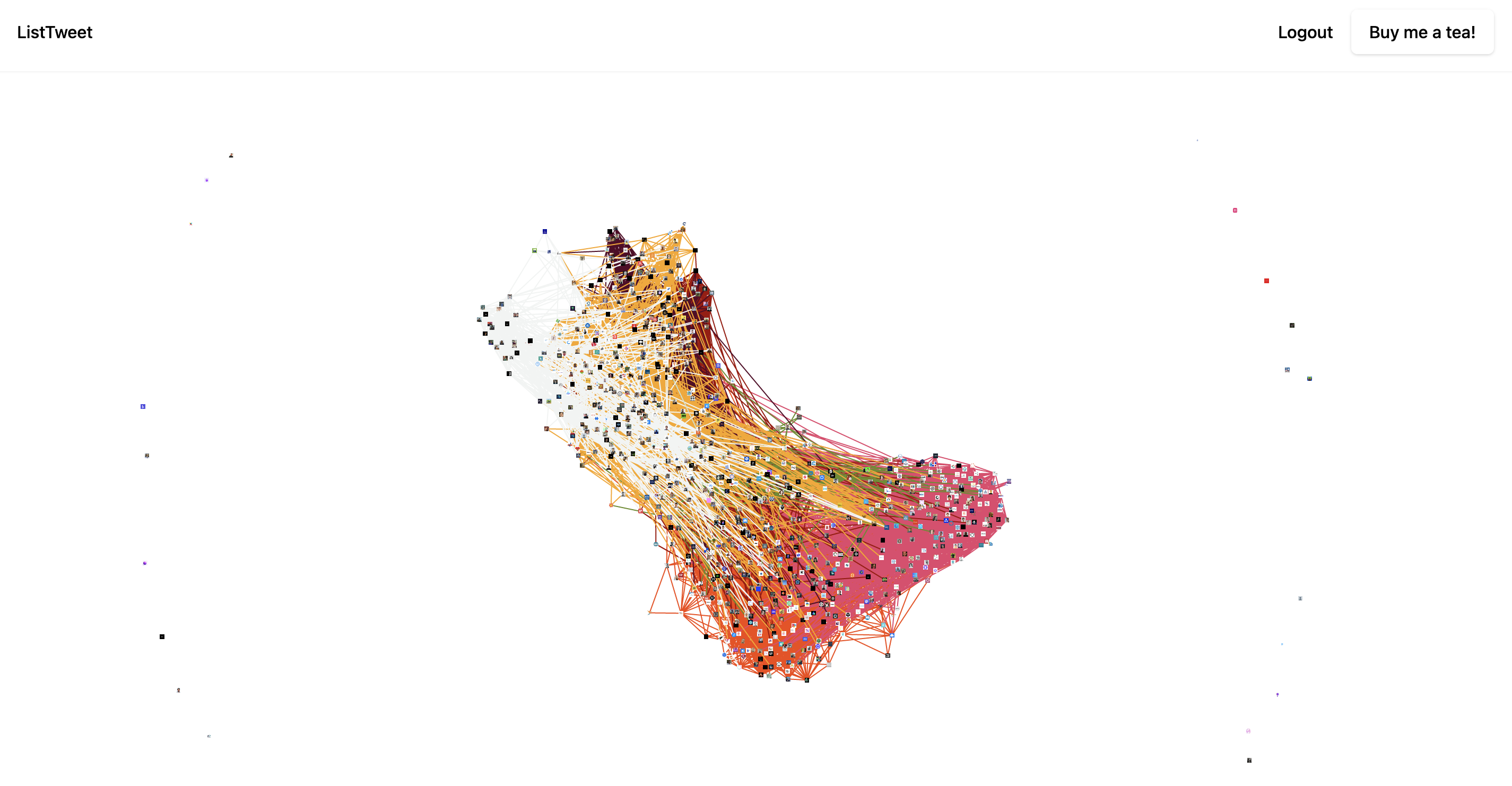
Almost 15 months after my launch of ListTweet I saw someone else on my Twitter feed discover that list creation on Twitter is broken. Lo and behold they were building an application to help address the problem. Interestingly I had already given up hope that my application would ever be discovered and had even open sourced the product.
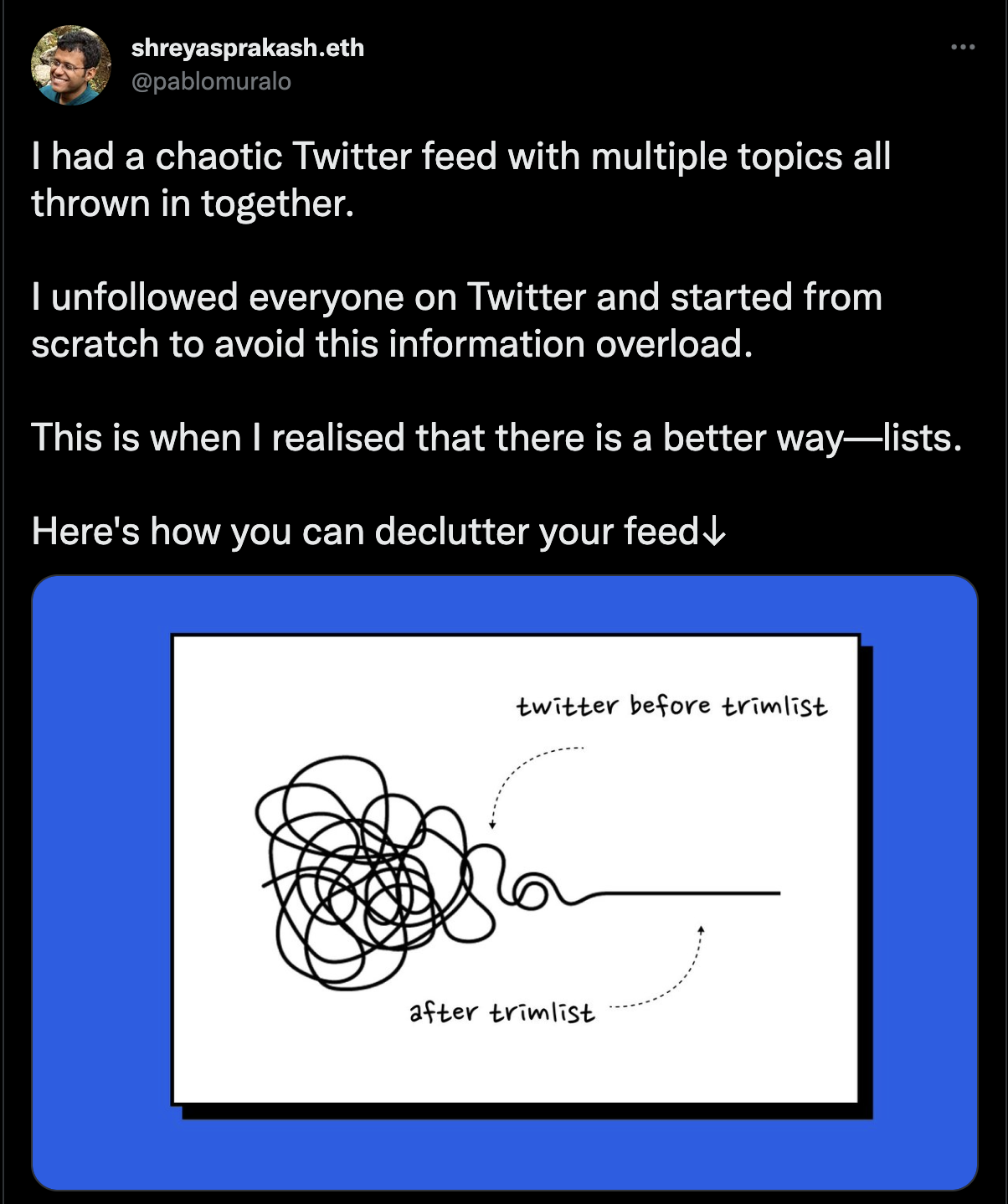
Why is it that someone is not able to discover prior work, even from their own twitter circle? What should exist for that to happen? How do we 'Google' who in the world has the same idea as mine?
Do we have an idea on how to represent any idea?! Do we have any idea on how to represent an idea?!
This question has been pondered by many including none other than the founder of the web Sir Tim Berners Lee who conceived the idea of the web of data a.k.a the Semantic Web.
URLs? What do they mean?
As we have seen, a tabular grid is quite handy to structure information. We can use separate grids to track different types of information and connect things in one grid to another through links. (Foreign keys from the relational database world, linked records from the Airtable world)
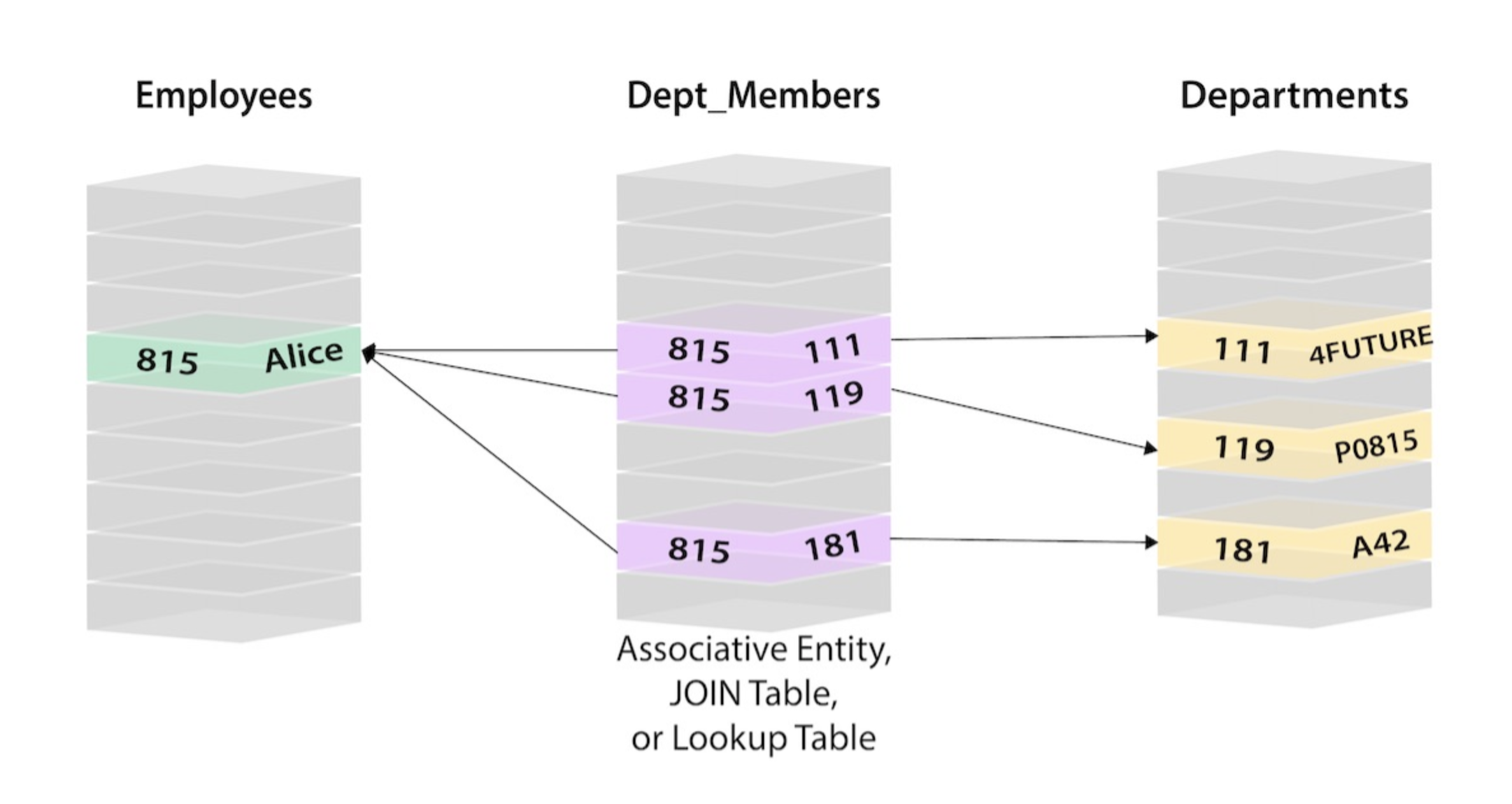
Another lens to view the tabular structure is the connected nodes (or graph) structure.
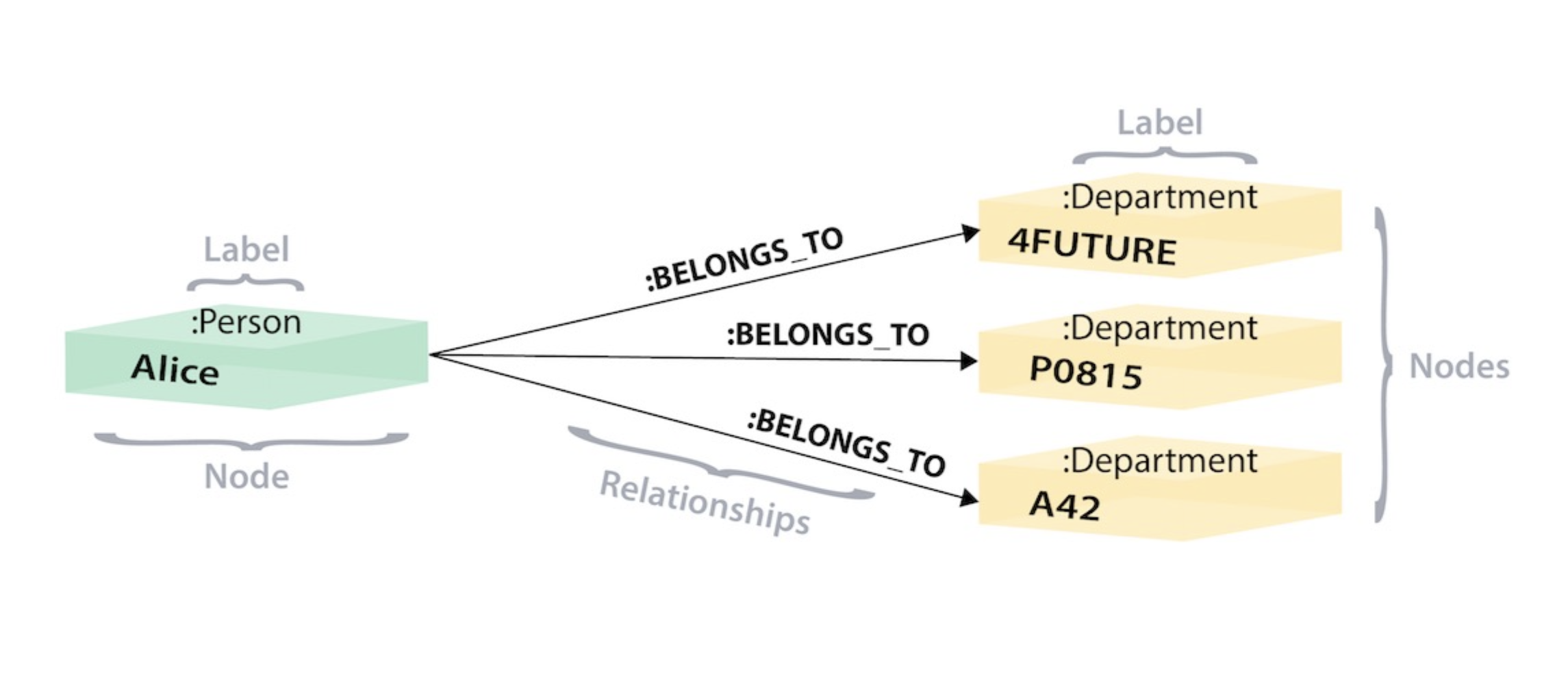
The advantage of the graph structure is the modelling flexibility and extensibility. We can arbitrarily connect each node to any other node via different types of relationships. This is the fundamental idea behind the semantic web.
The World Wide Web Consortium (W3C) has published standards to agree and interoperate on how to publish data structured as graphs on the open web.
Despite being in development for more than 25 years the semantic web hasn't really taken off. Much has been said about why the semantic web hasn't really taken off.
At the heart of it web applications that facilitate creating structured content on the internet have no incentives to share the hard collected data on the open web in an interoperable standard.
Especially when the entire point of the business is to lock that data down and not share it at all costs.
But accessible organised knowledge about the world is paramount. We can even set a price to it. The asking rate is about 300$ for about 10,000 things.
Another consequence of organised information not being accessible is the enormous cost of discoverability on the web. In 2022 for the first time ever world wide online ad spend is set to cross $600B.
The extent of information organised in the world should be measured by the reduction in global ad spend. Global ad spend is a sort of tax for discovery. We need to find avenues of reducing this burden. My current thesis is that access to knowledge commons combined with the information of who has published the information and how we know them can help significantly in discoverability both from the perspective of people looking for answers and entities looking to be discovered.
Decentralised dilemma
The W3C approach of standards is on the assumption that people self-publish their data. But as a world we aren't there yet. It's the same reason why we use gmail despite email being an open protocol. We still continue to use Twitter despite ActivityPub. People aren't managing their own servers on their own terms. It's just easier to use centralised services and get the job done. The incentives are also aligned for organisations to build such centralised platforms. For now.
Are there centralised platforms to organise all human knowledge? There are!
One of the earliest projects in this space was freebase. Freebase got acquired by Google and was eventually shut down. Freebase at Google evolved to be the Google Knowledge Graph. The data and the crowdsourcing part of freebase currently exists as wikidata.
The problem with Wikidata is the same as that on Wikipedia. You and I aren't on it. Your dog doesn't have a wikipedia page (unless you're the queen) and would be taken down if you were to create one. The problem is of notability. It's a place only for notable things.
We don't just need a knowledge base for notable things, we need one for everything. You should be able add yourself or your local grocery store to a public common database for everyone to use.
There are other approaches where we structure information for certain verticals. For food, retail outlets, startups and investments, saas products. But each of these platforms is another silo. The data is neither part of the commons nor allows one to interlink to other things.
We need centralised platforms to structure all human knowledge and make it accessible.
Golden is pursuing this goal. They're also exploring incentivising contributions from everyone through tokens.
Needless to say, this is a very exciting space for me. Last month I started working on a proof of concept (https://crowww.in) for a crowdsourced knowledge graph.
As a starting point I've indexed the 'Ecological Wealth' database curated by Ganeshram from Rainmatter Foundation. You can currently look up 37k+ entities and 140,000+ relationships related to ecology in India.
You can also view the entire data on this massive Airtable base.
Would love to hear your thoughts on this!
“Eventually everything connects - people, ideas, objects.
The quality of the connections is the key to quality per se."
Charles Eames